Early computers had direct access to physical memory, so that it was impossible to run two programs in memory at the same time, think why?
Three storage models are given below.
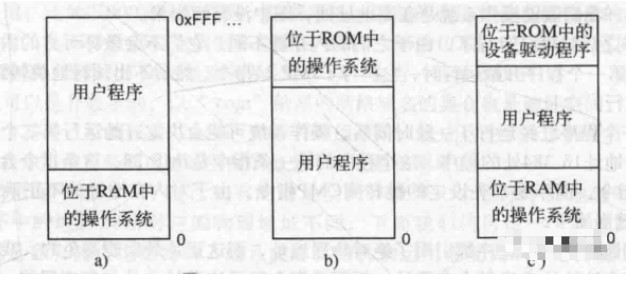
Both the first and the third are not commonly used anymore because the user program may destroy the OS in case of an error, and when the program is loaded in the above way, the newly loaded program will overwrite the previously loaded program. The only way to parallelize is to use multiple threads, but it will share information, so it is not feasible.
Later, the concept of memory keys was proposed to distinguish between multiple programs in memory, when multiple programs can be loaded in memory, but a program may crash because of the jmp instruction jumping to another program. This is because of the use of absolute address problems, a solution is to use the static relocation method, such as a program loaded to 16000 address bits, then the number of addresses in the program to add the constant 16000, although this method is generally speaking feasible, but it is impossible to identify it is relocated address or not relocated address, to an access address, that the access address plus or minus 16000, and the method will slow down the loading speed.
An abstraction of memory: address space

For multiple programs to be in memory at the same time two problems need to be solved: protection and redirection. We want each program to have its own separate set of address spaces.
A simple way to do this is to use dynamic relocation, using the base address register (which holds the program start address) and the bounds register (which holds the program size). When an instruction reads or writes a data word, the CPU hardware adds it to the value in the base address register before sending it to the memory bus, and determines whether the summed instruction is out of bounds. But doing the addition and comparison operations each time would be slow.
The advent of swap technology
It is unlikely that all processes will be loaded into memory. One strategy is to store idle processes on disk and load the entire process that needs to be used into memory; another strategy is virtual memory
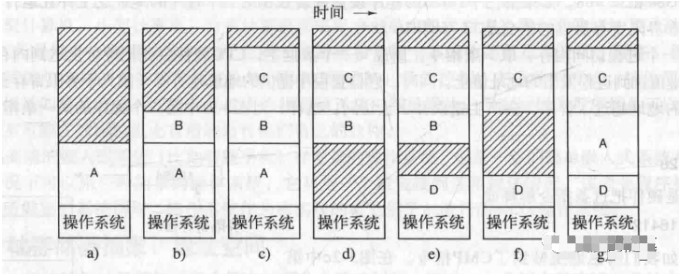
Swaps create multiple free areas in memory, and it is possible to combine these smaller memory areas into larger ones by moving all memory down as far as possible, which is called memory compression, but this operation is usually not performed because it is very time consuming and the OS needs to allocate memory exactly to the size it needs.
But if the data segment can grow, for example, many programming languages allow dynamic allocation of memory from the heap. So we can reserve some space for it.
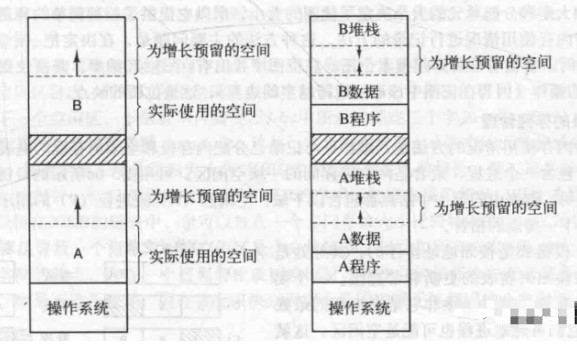
The stack, which holds private variables and return addresses, grows downward. The data segment is used as a heap for variables to be dynamically allocated and released, and grows upward.
Free memory area management – bitmap approach
Memory may be divided into allocation cells as small as a few words or as large as several kilobytes. Each allocation cell corresponds to a bit in the bitmap, with 0 indicating free and 1 indicating occupied. When allocating a process with k allocation units, it is very time consuming to look up k consecutive allocation units in the bitmap for allocation.
Free Memory Area Management – Chained Tables
Another way is to maintain a chain table of allocated memory segments and free memory segments, and let’s say that when process X finishes it needs to merge memory at the same time.
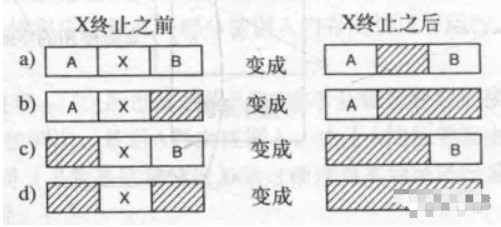
Of course, there are many algorithms to allocate memory here, from first adaptation method, next adaptation method, best adaptation method (which will generate more small free areas, consider worst adaptation method), etc.
Virtual memory
To prevent a program from getting too big, the overlay block method was first used, i.e., manually cutting the program into small blocks, but how to cut it was a problem. So the problem was simply left to the computer, and virtual memory was born. The basic idea is this.
Each program has its own basic space, and this space is divided into blocks, each called a page and pages. (Note: virtual memory is the use of disk space to expand memory, hence the name virtual)
A diagram will make it clear.
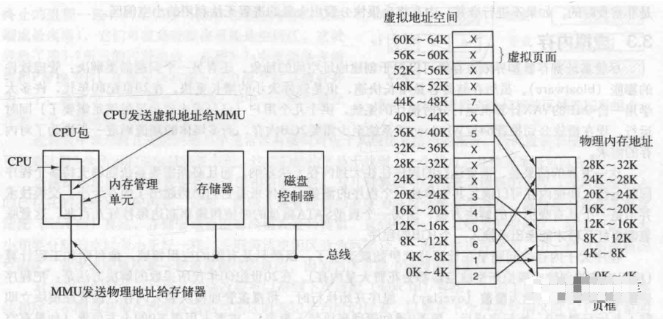
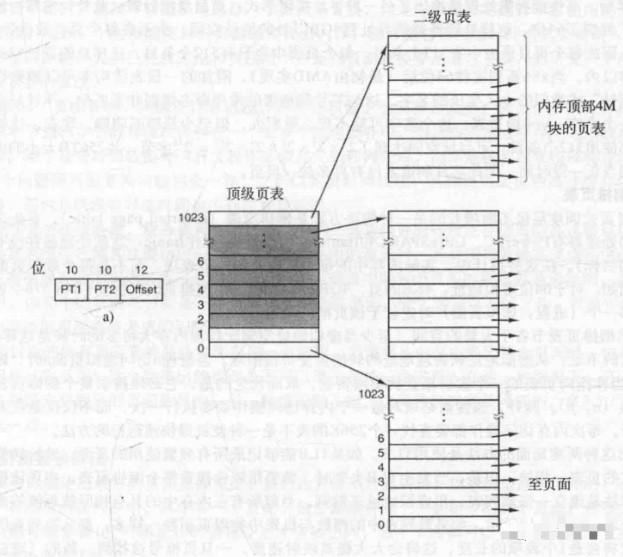
Here, we manage pages by page table (base address + offset), and we can also add TLB (block table), the content of computer composition principles, right? Sometimes, a single page table is not enough to represent the page, so we can use a secondary page table or a multi-level page table, look at the following diagram.
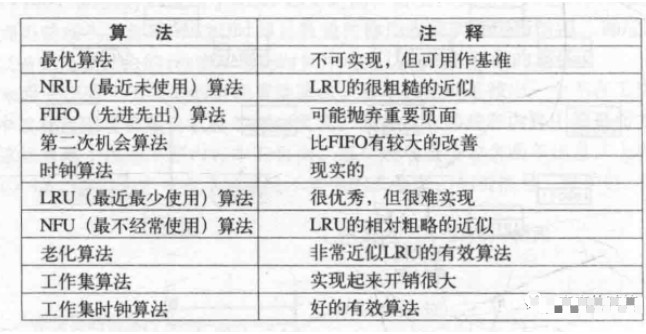
When considering how to swap, a page that is considered to swap out the minimum survival time in a single process is called a local page replacement algorithm, and a page that is considered to swap out the minimum survival time in the entire memory is called a global page replacement algorithm. Usually the global algorithm is better. Another way is to allocate pages equally for the process and put the rest in the common pool.
We can also use the method of testing the out-of-page interruption rate.
Also, we should choose the right page size. In terms of sharing, generally read-only pages can be used as shared pages to reduce memory consumption.
Shared libraries
Static linking of .o programs can cause significant memory consumption because of linking different library files which are loaded directly into memory. However, shared libraries (also known as dynamic link libraries, DLLs), will only load a small section of stub routines that can bind the called function at runtime, i.e. whatever function is used, only the corresponding page is loaded instead of the whole file. Of course, if other programs load the shared library, this program does not need to load it.
In addition, if the DLL file is updated, it does not need to be recompiled and executed, the user only needs to download the updated DLL file to use it the next time it is started.
To see two processes using a shared library, you need to use the relative address.

Shared libraries are actually a special case of memory mapped files.
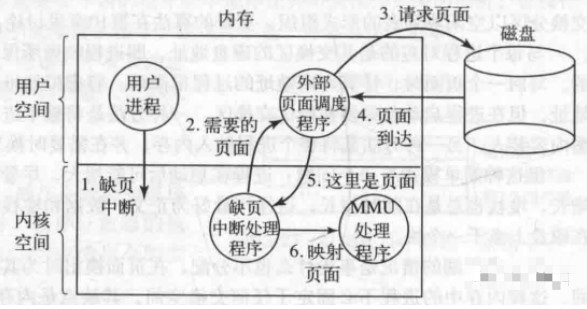
How do I perform out-of-page interrupt handling?