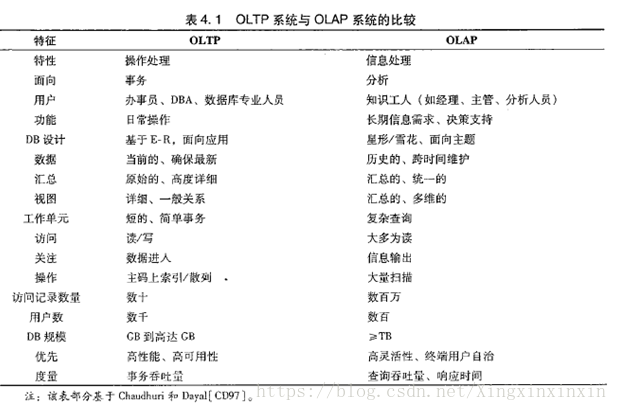
01、Overview
02、What is column storage?
03、Comparison in data writing
04、Comparison in data reading
06、Advantages and disadvantages
07、Applicable scenarios of column storage
08、Final summary as follows
01、Overview
Currently there are two options for big data storage: row storage (Row-Based) and column storage (Column-Based).
02、What is column storage?
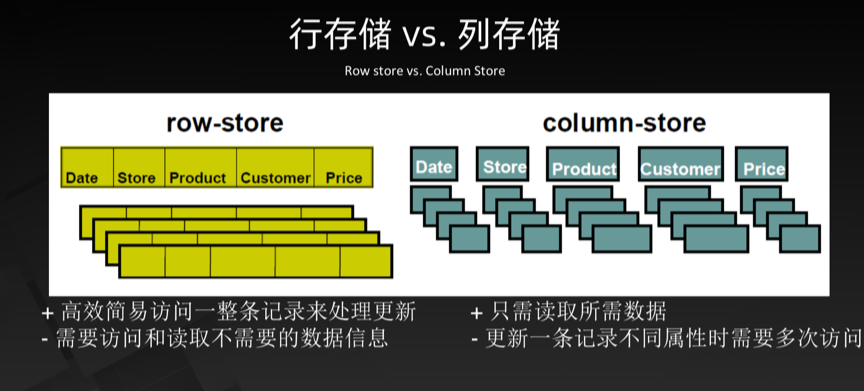
Column-based storage (column-based) is relative to the traditional relational database row-based storage (Row-basedstorage). Simply put, the difference between the two is how to organize the table.
Ø Row-based storage storesatable in a sequence of rows.
Ø Column-based storage storesatable in a sequence of columns.
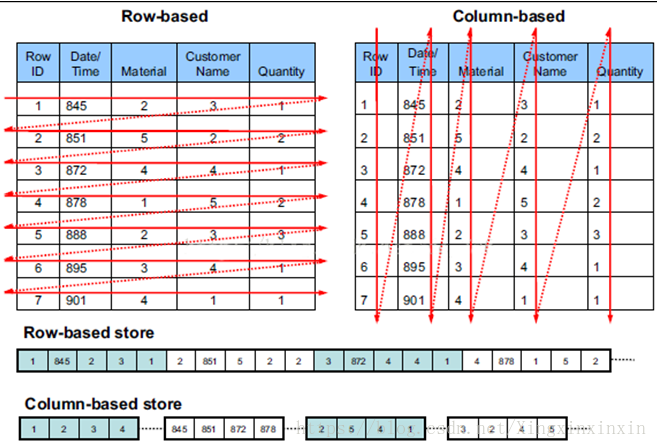
As you can clearly see from the above diagram, the data of a table are kept together under row storage, but they are kept separately under column storage. So they have these advantages and disadvantages compared as follows.
- Comparison in data writing
1) Writing to row storage is done once. If this writing is built on the operating system’s file system, the success or failure of the writing process can be guaranteed and the integrity of the data can therefore be determined.
(2) Column storage requires splitting a row record into a single column, so the number of writes is significantly higher than row storage (which means more head scheduling, which takes time, usually 1ms~10ms), plus the time spent on moving and positioning the head on the platter, so the actual time consumption is much higher. Therefore, line storage has a great advantage in writing.
3) There is also data modification, which is actually a writing process. The difference is that data modification is to mark the records on the disk for deletion. Row storage is written once in the specified location, column storage is positioned on the disk to multiple columns are written, the process is still row storage column times. Therefore, data modification is also dominated by row storage.

04、Comparison in data reading
(1) data reading, row storage will usually read out a row of data completely, if only a few of the data, there will be redundant columns, for the sake of reducing processing time, the process of eliminating redundant columns is usually carried out in memory.
2) Column storage reads a section or all of the data of a collection each time, and there is no redundancy problem.
3) Data distribution for both stores. Since each column data type of the column store is homogeneous, there is no problem of duality. For example, if the data type of a column is integer (int), then its data set must be integer data. This situation makes data parsing very easy. In contrast, row storage is much more complicated because multiple types of data are stored in a row of records, and data parsing requires frequent conversions between multiple data types, an operation that consumes CPU and increases the parsing time. Therefore, the parsing process of column storage is more conducive to analyzing big data.
4) Comparison in terms of data compression and more performance reading
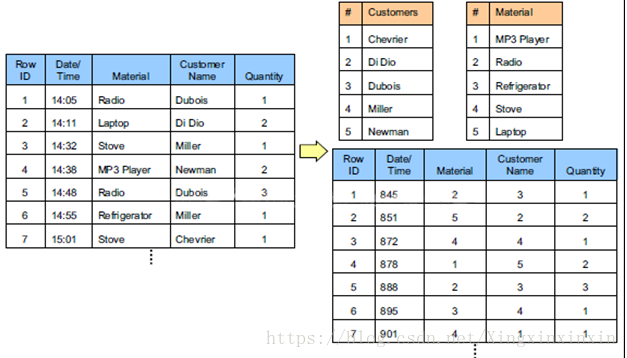
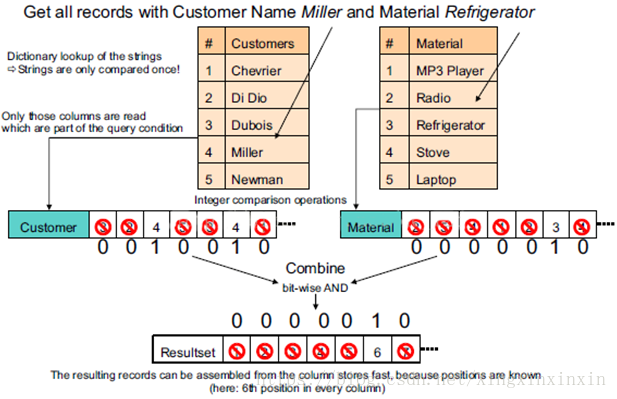
- Advantages and disadvantages
Obviously, both storage formats have their own advantages and disadvantages.
(1) row storage is written at once, consuming less time than column storage, and can ensure the integrity of the data, the disadvantage is that the data reading process will generate redundant data, if only a small amount of data, this impact can be ignored; the number of large may affect the efficiency of data processing.
(2) column storage in the write efficiency, to ensure data integrity are not as good as row storage, its advantage is that in the reading process, will not generate redundant data, which is not high data integrity requirements of the field of big data processing, such as the Internet, as important.
The characteristics of each of the two storage formats determine their use scenarios.
07、Applicable scenarios of column storage
(1) In general, an OLAP-type query may need to access millions or even billions of data rows, and the query is often concerned about only a few data columns. For example, if you query the top 20 products with the highest sales volume this year, this query only cares about three data columns: time (date), product (item) and sales amount (sales amount). Other data columns of the product, such as product URL, product description, product store, etc., are not meaningful to this query.
The columnar database only needs to read the data columns that store “time, item, sales amount”, while the row database needs to read all the data columns. Therefore, the columnar database greatly improves the efficiency of OLAP large data volume queries
OLTP OnLine TransacTIonProcessor online online transaction processing system (such as Mysql, Oracle and other products)
OLAP OnLine AnalaysierProcessor Online online analytical processing system (such as Hive Hbase, etc.)
(2) Many columnar databases also support column group (called locality group in Bigtable system), which means that the individual values of multiple data columns that are often accessed together are stored together. If the data columns read belong to the same column group, the column database can read the values of multiple data columns from the same place at one time, avoiding the merging of multiple data columns. Column family is a kind of row and column hybrid storage mode, and this mode can meet the query requirements of OLTP and OLAP at the same time.
(3) In addition, because of the high data repetition of the same data column, columnar databases have a great advantage when compressing.
For example, Google Bigtable columnar database can achieve a compression rate of more than 15 times for web page library compression. In addition, you can do special index optimization for columnar storage. For example, if the gender column has only two values, “male” and “female”, a bitmap index can be created for this column.
As shown in the figure below
The corresponding bitmap for “male” is 100101, which means that the first, fourth and sixth row values are “male”
The bitmap corresponding to “female” is 011010, which means that the value of the 2nd, 3rd and 5th rows is “female”
If you need to find the number of males or females, you only need to count the number of times 1 appears in the corresponding bitmap. In addition, the repetition of 0 and 1 is high after the bitmap index is established, so a special encoding can be used to compress them.
Of course, if the amount of data involved in each query is small or most queries require whole rows of data, the columnar database is not applicable.
- Finally, the summary is as follows
① Data is stored by rows.
②queries without indexes use a lot of I/O. For example, general database tables are built indexes to speed up query efficiency through indexes.
③It takes a lot of time and resources to build indexes and materialize views.
④In the face of query demand, the database must be heavily inflated to meet the demand.
The characteristics of columnar database are as follows.
① Data is stored by column, i.e. each column is stored separately.
② Data is indexed.
③Only the columns involved in the query are accessed, which can greatly reduce system I/O.
④Each column is processed by one thread, i.e., high concurrent processing performance of the query.
⑤ Consistent data types and similar data characteristics can be efficiently compressed. For example, there are incremental compression and prefix compression algorithms are customized based on the type of column storage, so the compression ratio can be substantially improved, which is beneficial to the storage and network output data bandwidth consumption.
Reviewed and edited by Zixiong Tang